Workflow
At this point we would like to introduce you to a possible workflow in an international project. The individual tiles with different topics each represent a specific part of the workflow and are written from the point of view of a project member. Due to the pilot projects, there is currently only an example from the Department of Computer Science. Examples from other departments will follow as soon as projects have been completed there as well.
Branches
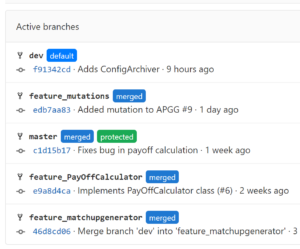
We have decided to use at least two branches for the development. A main branch reserved for release versions and a development branch used for development versions of the software. This is based on the idea that the master branch always creates a working release build at compile time. The dev branch works the same way, with the small difference that this branch is compiled into a working dev version.
When a new feature is to be implemented, we create a new branch of dev. A new branch is subject to a strict naming convention. Each of these “feature branches” must begin with “feature_”. Each branch includes a single feature that can be developed without disrupting or breaking the dev branch.
Upon completion of the feature, a merge request is created to merge the code from its branch into dev.
Merge Requests:
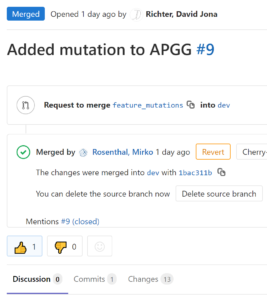
Merge requests are necessary to merge code from a feature branch into the dev branch. To create a merge request, the maintainer enters the source and target branches (dev). The title can then be changed and comments added to the Feature branch.
After the merge job is created, it had to be reviewed by a second developer before it could be implemented. Accidental errors are to be avoided by the “4-eye-principle”. The second developer can accept or reject the request. In case of rejection, the reason will be published in the comments section under the merge request.
If everything goes according to plan, the feature branch is merged with the dev branch, and if selected, the source branch is then deleted.
Commits
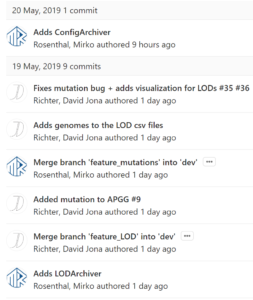
We have tried to use atomic and meaningful commit messages. Atomic in this case means that we tried to commit only one change at a time. If someone wants to know in the future what changes have been applied to a particular file, the change and its reason are immediately visible. Otherwise, you might have to check a lot of commit messages.
It also gives us a much better overview of what things have been changed and why. Gitlab also allows us to solve cross-referencing problems, merge requests, and transfer hashes. This makes it easy to jump from a particular commit to a particular problem or merge a request.
Issues
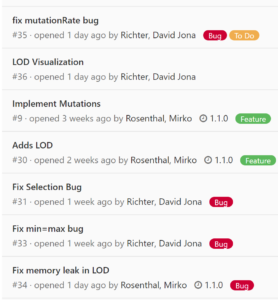
The “Issues” section is one of the most important tools during the project. It gives us a detailed overview of bugs, features, changes or ideas.
In this section, we can discuss bugs and their reproduction steps, or simply write down our ideas. Each of these issues gets a “bug”, “change” or “feature” label. Some of these issues can also be combined into a milestone to help determine the amount of work required for the next meeting.
The Issue Board provides an excellent overview of current tasks for project participants and maintainers alike.
Weekly Meetings
![]()
In addition to the internal list of topics, weekly meetings with the supervising professor in Germany and with the partners of the University of Michigan take place via web conference. In this meeting, the current version of the software is presented and problems, obstacles and ideas that have arisen since the last meeting are discussed.
After solving the concrete problems, bugfixes and new features will be discussed, which will then be implemented in the following week. All this information will be converted into label issues and combined into a new milestone.
Milestones
Milestones are used to summarize a number of problems. Each milestone is a releasable software that is presented in a meeting.
These milestones help maintain motivation by showing the progress of each milestone. Project participants enjoy when all topics can be completed and they can see how the percentage of a milestone has increased.